AI 工程的三次进化:从 Prompt 到 Context 到 Harness
AI 工程的三次进化:从 Prompt 到 Context 到 Harness
裸奔的 LLM 就像一颗没有操作系统的 CPU——算力惊人,但无法独立完成任何实际工作。
这个类比来自 Akshay Pachaar 的一张图,把计算机体系结构和 LLM Agent 做了逐层对照:LLM 对应 CPU,上下文窗口对应 RAM,向量数据库对应硬盘,工具集成对应设备驱动,而 Agent Harness 对应的正是操作系统。
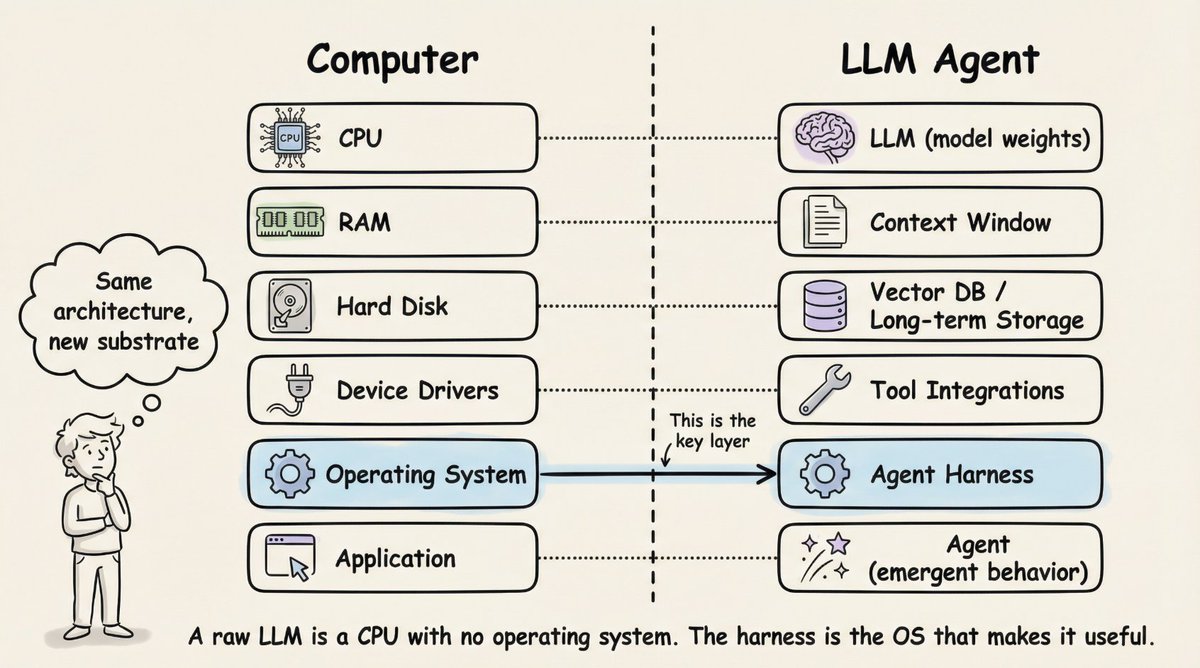
CPU 再强,没有操作系统就只是一块芯片。同理,模型再聪明,没有 Harness 就只是一个聊天接口。
过去三年,AI 工程领域经历了三次重心转移,分别对应三个关键词:Prompt Engineering、Context Engineering、Harness Engineering。三者逐层嵌套,各自解决不同层面的问题。
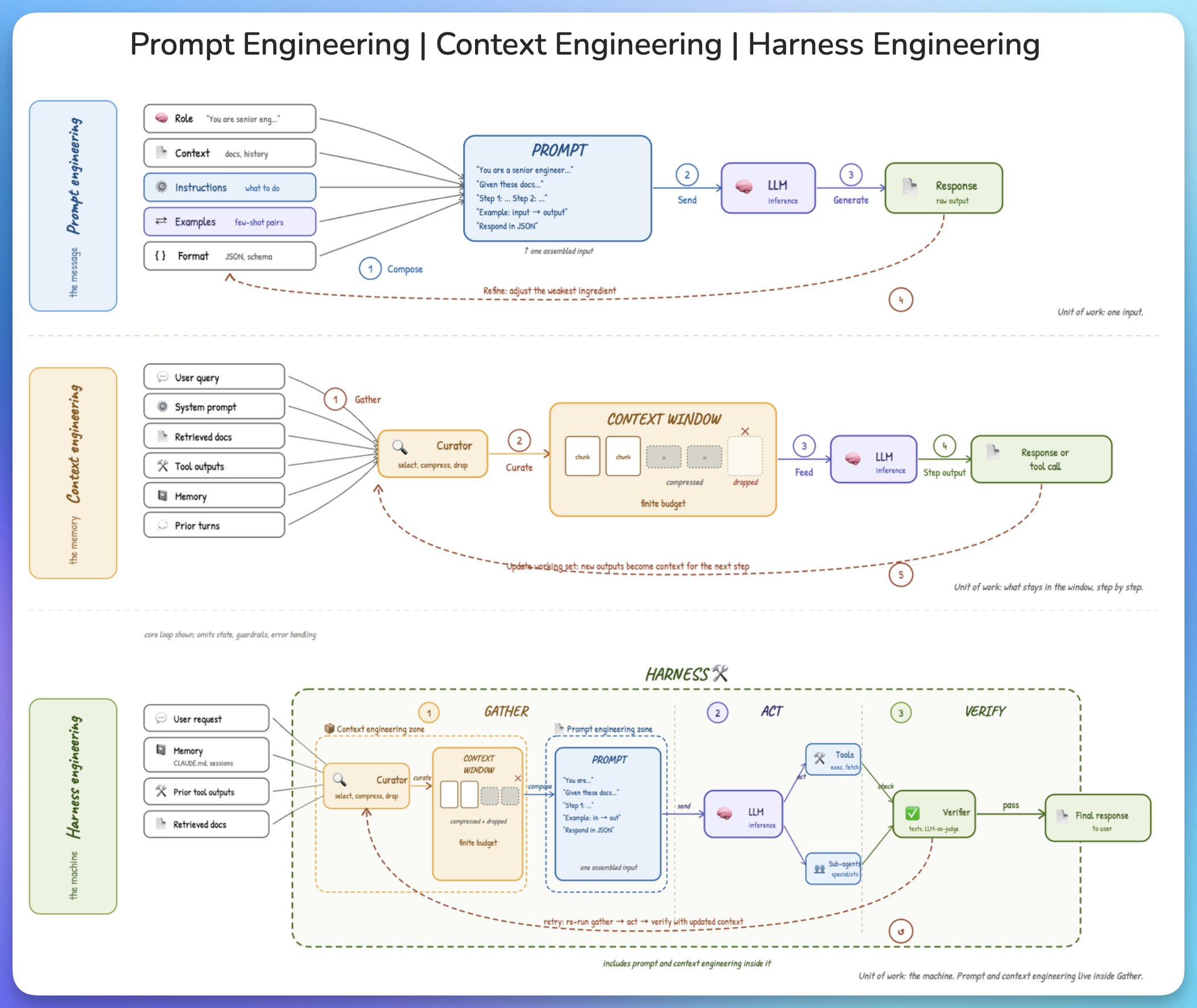
Prompt Engineering:把任务说清楚
Prompt Engineering 是所有人最先接触的 AI 技能。它关注的是一条消息本身如何组织:角色设定、目标描述、步骤拆解、输出格式、约束条件、示例。
它的工作单元是「一条输入」。你精心组装一段文本,发给模型,拿回一段输出。如果输出不满意,就调整措辞、补充示例、换一种问法。
当任务简单、上下文少、执行链路短时,Prompt Engineering 确实有效。好的提示词可以显著提升输出质量。
但 Prompt Engineering 有明确的能力边界:它无法解决模型拿不到正确信息的问题,无法处理工具调用失败,无法管理跨步骤的状态,也无法验证输出的正确性。所有这些问题都在提示词之外。
Context Engineering:让模型看到正确的信息
当 AI 从单轮问答进入复杂任务执行,问题就不再是「提示词写得好不好」,而是「模型在当下这一步到底看到了什么」。
上下文远不止用户输入的那句话。它可能包括检索出来的文档、历史对话摘要、用户偏好、数据库 schema、API 文档、工具调用结果、错误日志、业务规则、安全策略、当前任务状态。
Context Engineering 的目标是在每一步推理前,把「刚好足够、相关、可信、及时」的信息放进模型的上下文窗口。这件事涉及信息从哪里来、如何检索、如何排序、如何压缩、何时丢弃、何时刷新——本质上是一项系统设计工作。
大量 AI 系统的失败根源在上下文层面:检索到了旧文档、漏掉了关键约束、塞进了大量噪音、把不可信数据当成事实。在这种情况下继续调 Prompt,只是在表层修补。
Harness Engineering:为模型搭建操作系统
Harness Engineering 处理的是模型之外的一切。
如果 Prompt 控制一条消息,Context 控制模型看到的信息,那么 Harness 控制的是 Agent 所处的整个运行环境:任务编排、工具系统、权限边界、记忆机制、沙箱环境、验证循环、失败恢复、人工审批、日志与可观测性。
Agent = Model + Harness。 模型只是推理引擎,真正决定系统能否稳定工作的,是模型周围的 Harness。
Harness 的核心是一个循环:组装 Prompt → 模型推理 → 分类输出 → 执行工具 → 封装结果 → 更新上下文 → 回到起点。
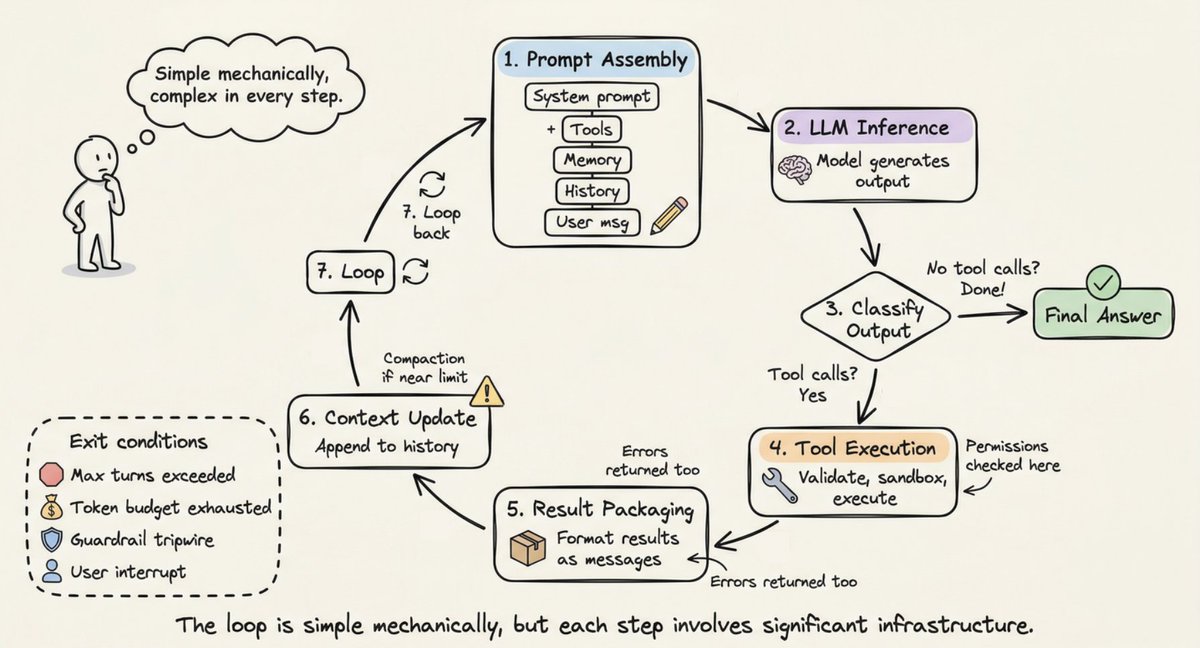
这个循环在机械结构上很简单,但每一步都涉及大量基础设施:Prompt 组装要拼接系统提示、工具定义、记忆和历史;输出分类要判断是最终答案还是工具调用;工具执行要做权限校验和沙箱隔离;上下文更新要在接近窗口上限时做压缩。退出条件包括达到最大轮次、耗尽 token 预算、触发安全护栏、用户中断。
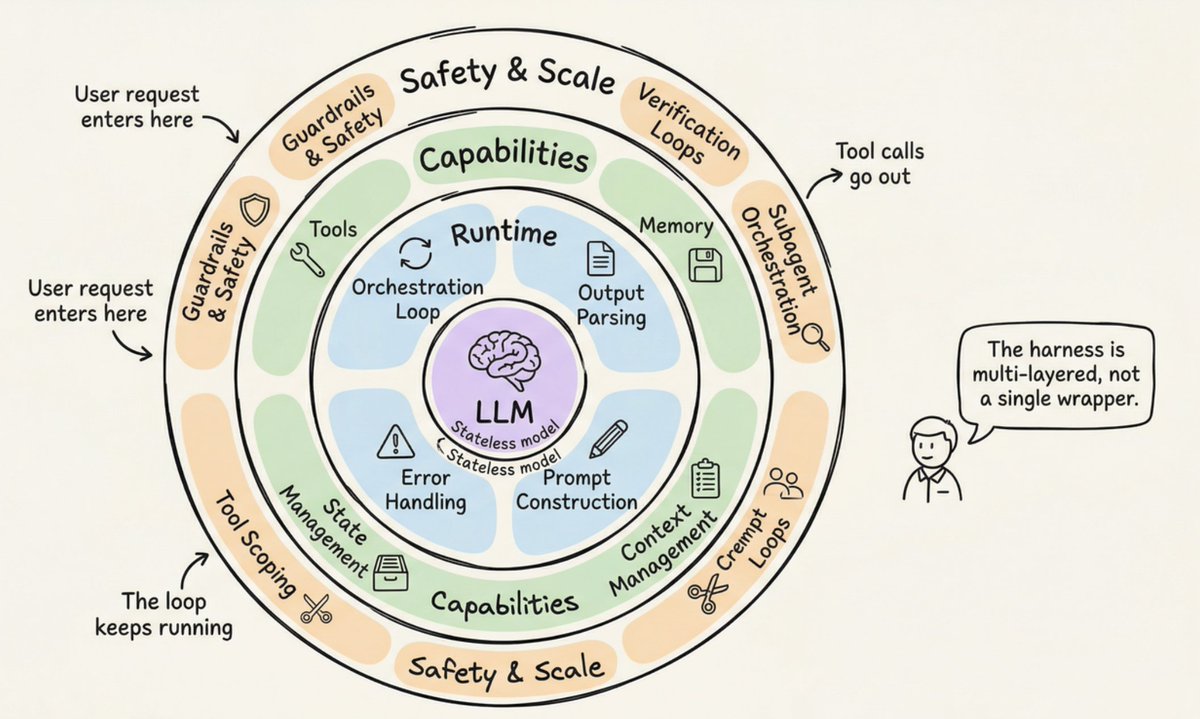
Harness 是一个多层结构,从内到外分为:Runtime(编排循环、输出解析、错误处理、Prompt 构建)、Capabilities(工具、记忆、上下文管理、状态管理、子 Agent 编排)、Safety & Scale(护栏、验证循环、工具范围限定)。
一个有用的比喻:Harness 是脚手架
有一个建筑工地的比喻能帮助理解 Harness 的本质。
Agent 是正在建造的大楼,LLM 是工人,Harness 是脚手架。脚手架本身不砌砖,但没有脚手架,工人就够不着高层。随着模型能力提升(工人越来越强),Harness 可以逐渐变薄——脚手架最终会被拆除。
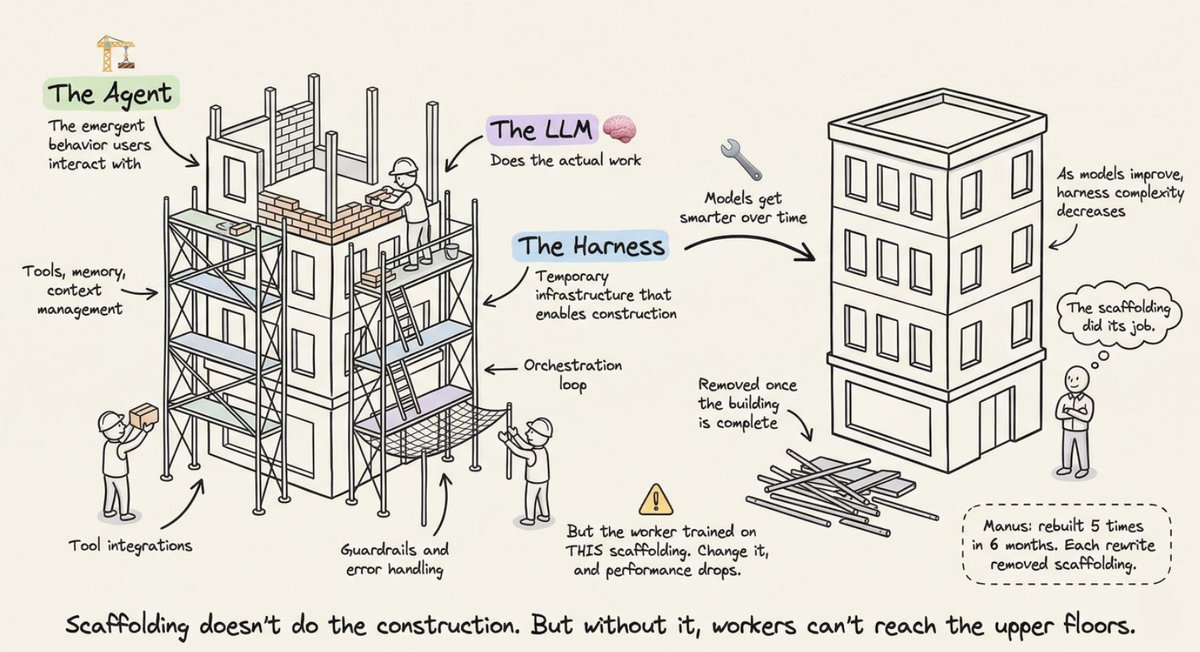
这意味着 Harness 是临时性的基础设施。它为当前阶段的模型能力做补偿,而模型一旦升级,部分 Harness 就可以简化。Manus 团队曾在六个月内重写了五次 Harness,每次重写都是因为底层模型变强了,原有的脚手架可以拆掉一部分。
设计 Harness 的七个关键决策
设计一个 Agent Harness 需要在多个维度做取舍。原文总结了七个核心决策点:
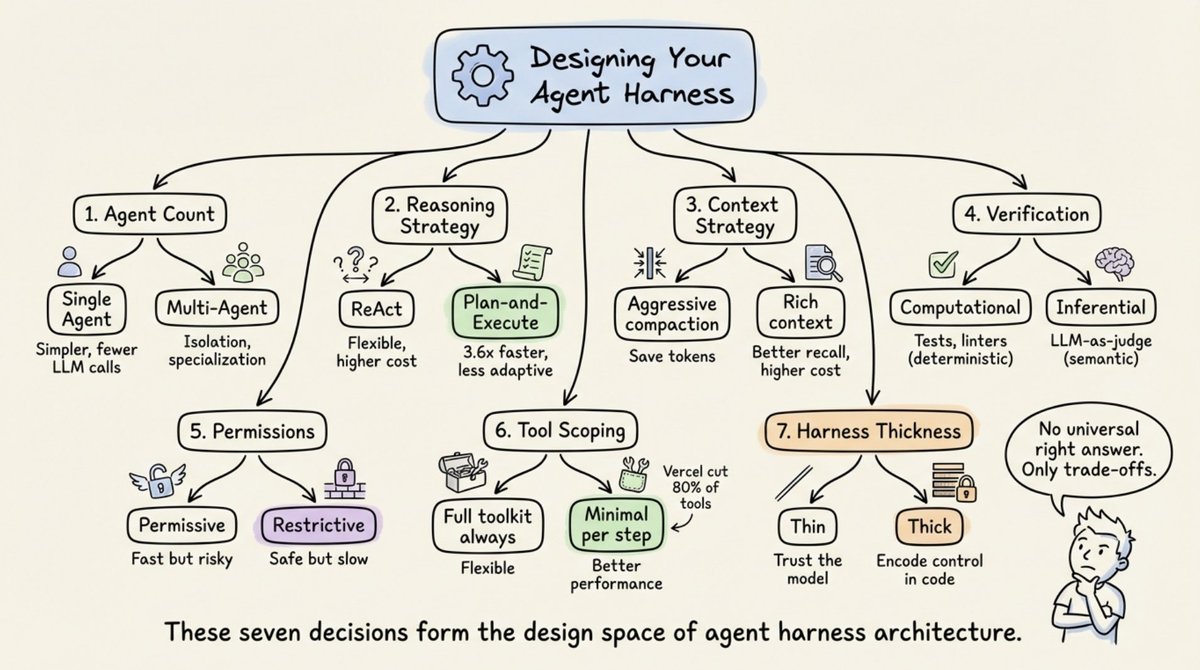
1. Agent 数量——单 Agent 更简单,多 Agent 支持任务隔离和专业化分工。
2. 推理策略——ReAct(边想边做)灵活但成本高;Plan-and-Execute(先规划再执行)速度快 3.6 倍但适应性差。
3. 上下文策略——激进压缩节省 token,丰富上下文提高召回率但成本更高。
4. 验证方式——计算型验证(测试、lint、类型检查)是确定性的;推理型验证(LLM-as-judge)可以做语义级评估。
5. 权限模型——宽松模式快但有风险,严格模式安全但慢。
6. 工具范围——始终提供全部工具更灵活,按步骤动态裁剪工具集性能更好(Vercel 曾通过裁掉 80% 的工具获得显著提升)。
7. Harness 厚度——这是最根本的架构赌注:你多大程度上信任模型自主决策,又多大程度上用代码显式编排流程。
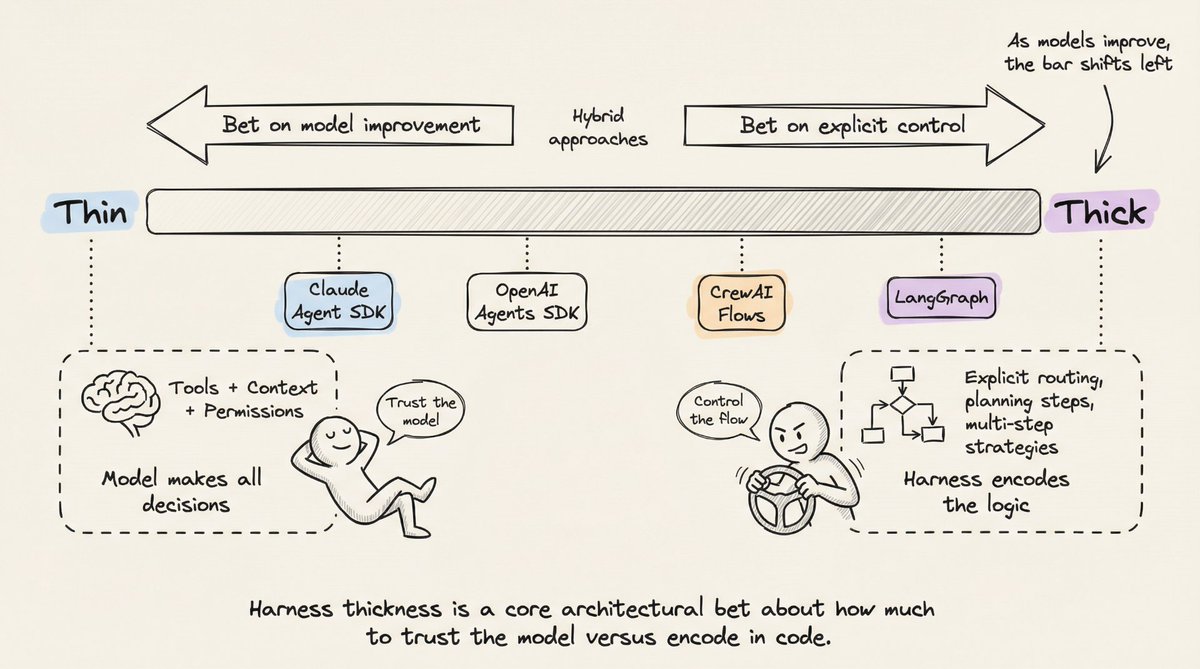
Thin Harness(如 Claude Agent SDK、OpenAI Agents SDK)提供工具、上下文和权限,然后信任模型做出所有决策。Thick Harness(如 LangGraph、CrewAI Flows)用显式路由、规划步骤和多步骤策略把控制逻辑编码在 Harness 里。
随着模型能力持续提升,这条线整体向 Thin 的方向移动。
主流框架的 Harness 实现对比
当前主流 Agent 框架已经在核心模式上趋同,但在具体实现哲学上各有取舍。
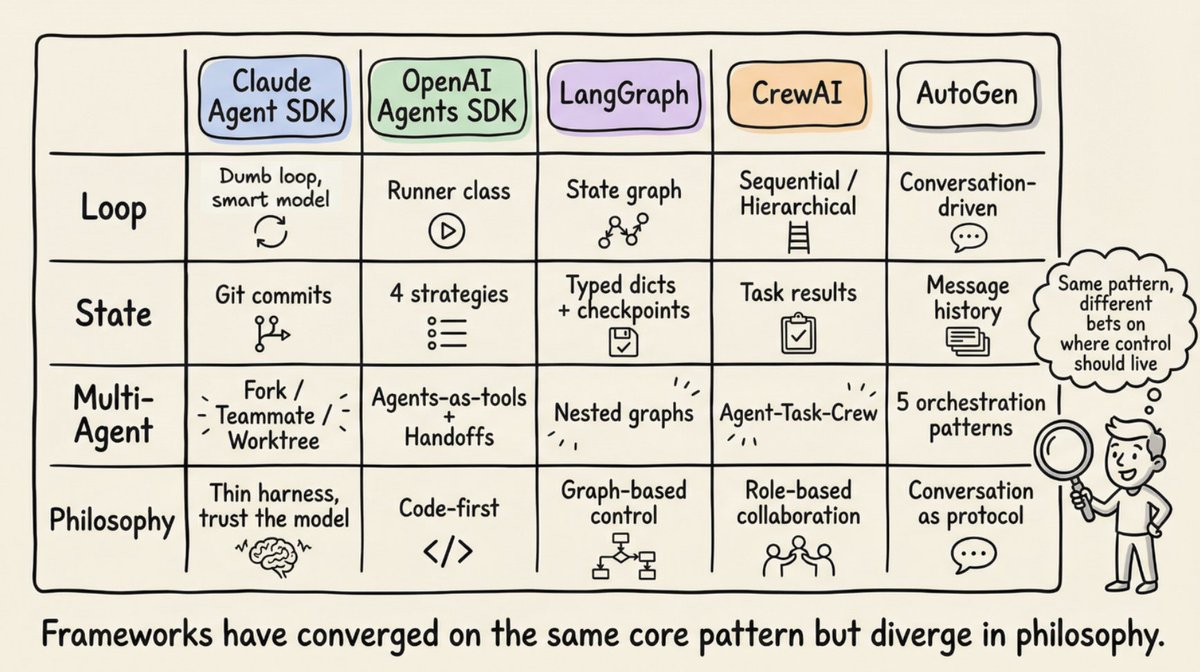
Claude Agent SDK 用最简循环 + 信任模型,状态管理靠 Git 提交。OpenAI Agents SDK 用 Runner 类 + 代码优先。LangGraph 用状态图做显式流程控制。CrewAI 按角色组织协作。AutoGen 把对话本身当作协议。
同样的核心模式,不同的控制权分配。选择哪种框架,本质上是在回答「在当前模型能力下,你愿意把多少决策权交给模型」。
三层架构的核心区别
| 维度 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 关注点 | 指令怎么写 | 信息怎么组织 | 系统怎么运行 |
| 控制范围 | 单条消息 | 一个任务的上下文窗口 | 整个 Agent 运行环境 |
| 典型问题 | 「我该怎么说?」 | 「模型需要知道什么?」 | 「系统如何稳定完成任务?」 |
| 常见失败 | 指令模糊、格式不稳 | 信息缺失、过时、噪音 | 工具失控、状态混乱、缺少验证 |
三者的关系是嵌套的:
Harness Engineering
└── Context Engineering
└── Prompt Engineering
好的 Prompt 仍然重要,但 Prompt 只是 Context 的一部分。好的 Context 同样重要,但 Context 只是 Harness 的一部分。
落地建议
如果你只是日常使用 ChatGPT 或 Claude 对话,Prompt Engineering 足够了——把任务说清楚、定义格式、提供示例。
如果你开始把 AI 接入真实工作流,就该投资 Context Engineering——维护项目规则文件、索引代码库、设计检索策略、压缩历史记录。
如果你要让 AI Agent 承担生产任务,就必须进入 Harness Engineering——重点从让模型「更聪明」转向让系统「更可靠」。
具体可以从六件事开始:
- 把团队约定写成机器可读的规则文件(
CLAUDE.md、AGENTS.md、项目开发指南),让 Agent 自动遵守。 - 把重复流程沉淀成 Skills、脚本或模板,减少每次用自然语言重新解释的成本。
- 把测试、lint、类型检查、构建验证接入 Agent 工作流,让验证成为默认动作。
- 给高风险工具设置权限边界——删除文件、写数据库、部署生产环境必须经过审批。
- 记录 Agent 的输入、工具调用、输出和错误,建立可观测性。
- 用评估集或真实任务回放衡量效果,不凭主观感觉判断。
工程严谨性换了位置,但没有消失
AI Agent 让很多人担心工程会变得随意——代码由模型生成,开发者只管点确认。
实际情况是,工程严谨性从「手写每一行代码」转移到了「设计系统如何约束、验证和放大模型能力」。在 Prompt 阶段,严谨性体现在指令是否清晰;在 Context 阶段,体现在信息是否准确、完整、及时;在 Harness 阶段,体现在系统能否让 Agent 在边界内行动、在错误后恢复、在输出前验证、在关键步骤接受人类监督。
AI 工程的竞争力不在某一句提示词,而在你能否构建一个让模型持续做对事的系统。
If you read this far — thank you.
Come tell me what you thought on X.