OpenAI VPT:通过观看视频学会玩 Minecraft 的 AI
OpenAI VPT:通过观看视频学会玩 Minecraft 的 AI
这篇论文讲了什么
2022 年,OpenAI 发布了一项名为 Video PreTraining(VPT)的研究,首次证明 AI 智能体可以通过观看大量无标注的互联网视频来学习执行复杂任务。研究团队选择 Minecraft 作为测试平台,训练出的智能体成为了第一个能在 Minecraft 中制作出钻石镐的 AI——这项任务即使对熟练的人类玩家来说也需要 20 分钟以上、超过 24,000 次连续操作才能完成。
这篇论文的核心贡献在于:它将互联网规模预训练的范式,从语言和图像领域,扩展到了序列决策领域。
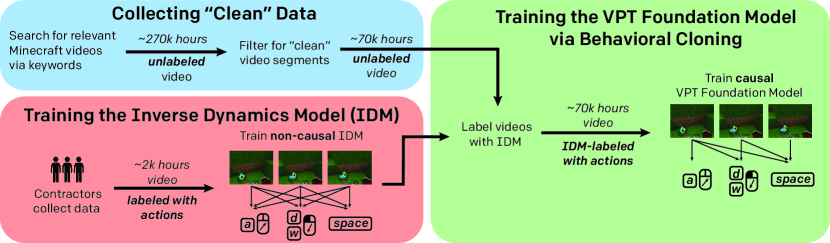
大语言模型的成功建立在一个前提上:互联网上存在海量的文本数据,而文本本身就是自带标签的——下一个词就是训练信号。图像领域也类似,大量带有文字描述的图片可以用来训练视觉模型。但在"行动"领域,情况截然不同。YouTube 上有数十万小时的 Minecraft 游戏视频,玩家们展示着各种复杂操作——砍树、合成物品、建造房屋、挖矿——但这些视频只有画面,没有记录玩家按了哪些键、鼠标移动了多少。我们能看到"发生了什么",却不知道"做了什么"。
VPT 用一种精巧的方式解决了这个问题:先用少量带标注的数据训练一个反向动力学模型(IDM),让它学会从视频画面反推玩家的操作;再用这个 IDM 给 7 万小时的互联网视频打上伪标签;最后在这些伪标注数据上训练出一个行为基础模型。少量昂贵的标注数据撬动了海量免费的无标注数据,数据效率比直接训练高出两个数量级。
为什么这篇论文重要? 传统的强化学习方法理论上可以让 AI 从零开始学习玩 Minecraft,但实际效果极差。像制作工作台这样看似简单的任务,需要大约 970 次连续正确操作,制作石器工具需要 2,790 次,制作钻石镐更是需要上万次。在如此庞大的动作序列中,纯靠随机探索找到正确路径的概率几乎为零。VPT 证明了一条不同的路:从人类行为的视频中学习,而非从零探索。
研究脉络:从视频中学习行动的前世今生
VPT 并非凭空而来。"从视频中学习动作"的想法,在 VPT 之前已有多条研究线在探索。
Torabi 等人在 2018 年提出的"行为克隆从观察"(Behavioral Cloning from Observation, BCO),最早使用反向动力学模型从无动作标注的观察中学习策略,思路和 VPT 的 IDM 高度相似。但 BCO 只在简单环境中验证,没有利用互联网规模的数据。视觉前瞻(Visual Foresight)方向则用动作条件化的视频预测模型做规划,在机器人推物体等任务上取得了效果,但依赖机器人交互数据,不是从互联网视频学习。ATC 等对比学习方法用前向动力学模型作为辅助任务学习视觉表征,为强化学习提供更好的特征输入,但没有直接从视频中提取动作。
VPT 的突破在于规模——把 IDM 标注无标签视频这个已有思路,推到了 7 万小时互联网数据的量级,证明了这条路可以在复杂开放环境中真正起作用。
VPT 发表后,这个方向迅速扩展到机器人和自动驾驶领域。Google 的 UniPi(2023)把序列决策问题转化为文本条件化的视频生成问题——不直接学动作,而是先生成未来的视频帧,再从中提取动作。NVIDIA 的 LAPA(ICLR 2025)直接继承了 VPT 的核心思想但更进一步——用 VQ-VAE 从视频帧之间学习离散的"潜在动作",完全跳过了显式的动作标注步骤,预训练效率比同类模型高 30-40 倍。GR-2(2024)在 3,800 万视频片段上预训练,再迁移到机器人操作。Physical Intelligence 的 π₀(2024)用 flow matching 生成高频连续动作,在折叠衣物等复杂任务上大幅超越基线。
从 VPT 到今天,核心趋势是三个方向的演进:数据来源从游戏扩展到真实世界,方法从显式的 IDM 标注过渡到隐式的潜在动作学习,架构从独立的行为模型走向与大语言模型融合的视觉-语言-动作(VLA)统一框架。
VPT 如何训练模型
VPT 的技术方案分为三个阶段,环环相扣。
第一阶段:训练反向动力学模型(IDM)
OpenAI 雇佣了 10 到 15 名承包商玩家,让他们在玩 Minecraft 的同时录制视频和操作记录(键盘按键、鼠标移动)。这批数据总共约 2,000 小时,成本约为每小时 20 美元,总花费约 9 万美元。
利用这批带标注的数据,研究团队训练了一个反向动力学模型(Inverse Dynamics Model, IDM)。IDM 的任务是:给定一段视频,推断玩家在每一帧执行了什么操作。
IDM 的一个关键设计是"非因果"的——它在预测某一帧的动作时,不仅可以看到之前的画面,还可以看到之后的画面。这让推断变得容易很多。比如,当你看到画面中一棵树突然消失了,即使看不到玩家按了什么键,也很容易推断出玩家执行了"攻击"操作。正因如此,IDM 的数据效率比直接训练行为克隆模型高出两个数量级。
IDM 拥有约 5 亿个参数,处理 128 帧连续画面(128×128 分辨率),采用 3D 卷积 + 非因果时序卷积 + ResNet + 残差注意力的架构。最终在键盘按键上达到了 90.6% 的准确率,鼠标移动的 R² 值达到 0.97。

第二阶段:用 IDM 标注海量视频,训练基础模型
有了高精度的 IDM,接下来就可以大规模标注互联网视频了。
研究团队从网上收集了约 270,000 小时的 Minecraft 视频,经过筛选过滤(剔除多人模式、延时摄影、Mod 内容等),保留了约 70,000 小时的"干净"视频片段。筛选过程使用了一个 SVM 分类器,在 8,800 张标注图片上训练而成。
然后用 IDM 对这 70,000 小时的视频逐帧标注动作——相当于给每一帧都打上了"玩家此刻按了什么键、鼠标移动了多少"的伪标签。
有了这些伪标注数据,研究团队通过行为克隆(Behavioral Cloning)训练了 VPT 基础模型。这个基础模型同样拥有 5 亿个参数,采用 Transformer 架构配合时序卷积,以 20 帧每秒的速率处理 128 帧的窗口,输入分辨率为 128×128。模型在 720 块 V100 GPU 上训练了约 9 天,共 30 个 epoch。
这里的因果结构设计与 IDM 不同:基础模型只能看到过去的画面来预测当前动作,因为在实际游戏中它无法看到未来。
VPT 没有简化游戏接口,而是使用与人类完全相同的原生操作方式:11 个二值键盘动作(前进、后退、左移、右移、跳跃、打开背包、潜行、冲刺、攻击、使用、丢弃)、9 个快捷栏切换(数字键 1-9),以及连续的鼠标移动(使用分档编码,每个轴 11 个 bin)。这意味着模型学到的操作能力可以直接迁移到任何使用鼠标和键盘的场景。
仅经过预训练、未经任何微调的基础模型就展示出了令人印象深刻的零样本能力:砍树和收集木材(纯 RL 从零开始几乎无法做到)、将原木合成木板、制作工作台(60 分钟内平均制作 0.19 个,人类承包商为 5.44 个)、在村庄中搜集食物、地形导航、游泳、柱状跳跃。这些行为从未被显式编程,完全是从 70,000 小时的视频观看中"学到"的。
第三阶段:微调
基础模型已经具备了相当的能力,但要完成更难的任务还需要进一步微调。VPT 使用了两种微调方式。
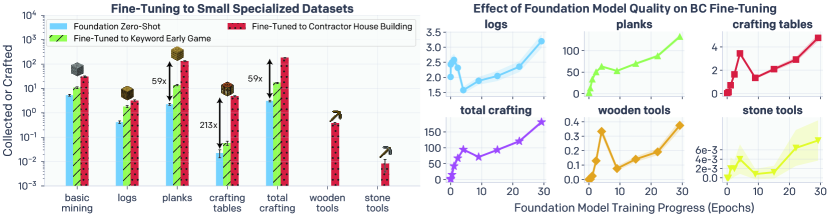
一种是行为克隆微调——用承包商数据中针对特定任务的子集对基础模型进行微调。例如,用"早期游戏"数据集微调后,模型制作工作台的效率提升了 2.5 倍,木板产出提升了 6.1 倍。用"建造房屋"数据集微调后,工作台制作效率提升了 213 倍,并且涌现出了制作木器工具(需要 1,390 次连续操作)和石器工具(需要 2,790 次连续操作)的能力。
另一种是强化学习微调——在行为克隆微调的基础上,进一步用强化学习优化特定目标。这里有一个重要的技术细节:研究团队引入了 KL 散度正则化,限制 RL 策略与预训练权重之间的偏离程度。没有这个正则化约束,模型会发生灾难性遗忘,连基本物品都无法制作。
最终在"10 分钟内从新世界制作钻石镐"的挑战中,从早期游戏模型出发进行 RL 微调的智能体达到了 2.5% 的成功率。作为对比,人类玩家的成功率是 12%,而从随机初始化开始训练的 RL 智能体成功率接近零。

数据规模的影响
论文中的消融实验揭示了一些重要的规模效应。
对于互联网视频数据量:使用 1 小时数据训练的模型只能完成基本导航;5,000 小时数据量时首次涌现出零样本制作工作台的能力;70,000 小时的完整数据集则在微调性能上带来了显著提升。石器工具的制作只在使用完整数据集时才涌现出来。
对于 IDM 的承包商标注数据量:少于 10 小时时,下游模型没有任何制作行为;50 到 100 小时时开始出现制作工作台的能力,之后增益趋于平缓。这意味着只需约 100 小时(约 2,000 美元)的承包商数据就足以支撑整个方法。


这组实验说明了 VPT 方法的数据杠杆效应——少量昂贵的标注数据(训练 IDM)撬动了大量免费的无标注数据(互联网视频),最终产出远超两者简单相加的效果。
局限性、潜力与展望
局限性
VPT 存在几个明显的局限。训练损失与下游性能之间缺乏一致的相关性,这使得模型选择和超参数调优困难重重——研究者无法通过观察 loss 曲线来判断哪个 checkpoint 会在实际任务中表现更好。模型无法根据自然语言指令执行特定任务,研究团队做了初步的文本条件化实验,但效果有限。此外,当前的验证仅限于 Minecraft 单一领域,尚未在其他游戏或真实世界任务中得到验证。
潜力
VPT 选择 Minecraft 并非偶然。Minecraft 使用标准的鼠标键盘操作,与日常电脑使用的交互方式一致。论文明确指出,VPT 的方法适用于任何拥有丰富无标注视频、且动作与观察之间存在清晰关系的领域——网页浏览、办公软件操作、甚至机器人控制,都是潜在的应用场景。研究团队估计仅 Minecraft 领域就还有超过一百万小时的额外视频数据可以利用。
更重要的是 VPT 验证的范式本身:用少量标注数据训练感知模型,再用感知模型标注海量无标注数据。这个"数据飞轮"思路已经被后续工作广泛采用。NVIDIA 的 LAPA 更进一步,用无监督方法学习潜在动作表示,完全省去了人工标注步骤。从 VPT 到 LAPA、π₀、GR-2,这条从视频中学习行动能力的技术路线,正在从游戏实验走向真实世界的机器人控制。
OpenAI 已在 GitHub 上开源了 VPT 的代码和模型权重,论文发表于 NeurIPS 2022。
Sources:
If you read this far — thank you.
Come tell me what you thought on X.